前置知识
CoalesceBatchesExec
定义如下:

简言之,CoalesceBatchesExec是合并较小Record Batch的操作符。HashJoin、FilterExec以及HashRepartitionExec均有可能产生较小的Record Batch。
datafusion/physical-optimizer/coalesce_batches.rs描述了相关逻辑:

背景
在 DataFusion 中,Hash Repartition操作是通过哈希一个或多个列,并使用hash % num_partitions 将它们划分到不同的分区中。
现有的实现为每个分区生成相应的indices并进行take array的操作。但这样的操作相对昂贵,因为我们需要在数组的不同位置访问数组 num_partitions 次,导致缓存不高效(尤其是当分区数量较高时)。
由于Hash Join可能产生小的Record Batches,RepartitionExec过后会进行CoalesceBatchesExec。
可行方法
- Bitmask/filter is a bit slower than current implementation.
- Flattening the nested Vec can improve performance for some queries. However, for some other queries, it can actually slow things down, possibly due to increased memory or less efficient access patterns.
- Prefix sum requires random access,which leads to bad performance.
这三种方法具体bench后性能反而要差一些。
直接优化这段代码行不通,就有了接下来的想法。在Repartition过后,我们可以直接引用原Record Batches,增加一个列标志当前行是否处于当前分区。这样做有以下好处:
- 避免了partition_iter中的take操作
- 避免了RepartitionExec过后的CoalesceBatchesExec
实现
假想有两张表。
t1:
| T1_ID | T1_name | T1_Int |
|---|---|---|
| 11 | 'a' | 1 |
| 22 | 'b' | 2 |
| 33 | 'c' | 3 |
| 44 | 'd' | 4 |
t2:
| T2_id | T2_name | t2_int |
|---|---|---|
| 11 | 'z' | 3 |
| 22 | 'y' | 1 |
| 44 | 'x' | 3 |
| 55 | 'w' | 3 |
现有sql语句:
SELECT t1_id, t1_name, t2_name FROM t1 LEFT JOIN t2 ON t1_id = t2_id AND t2_name >= 'y';
Physical plan 如下:
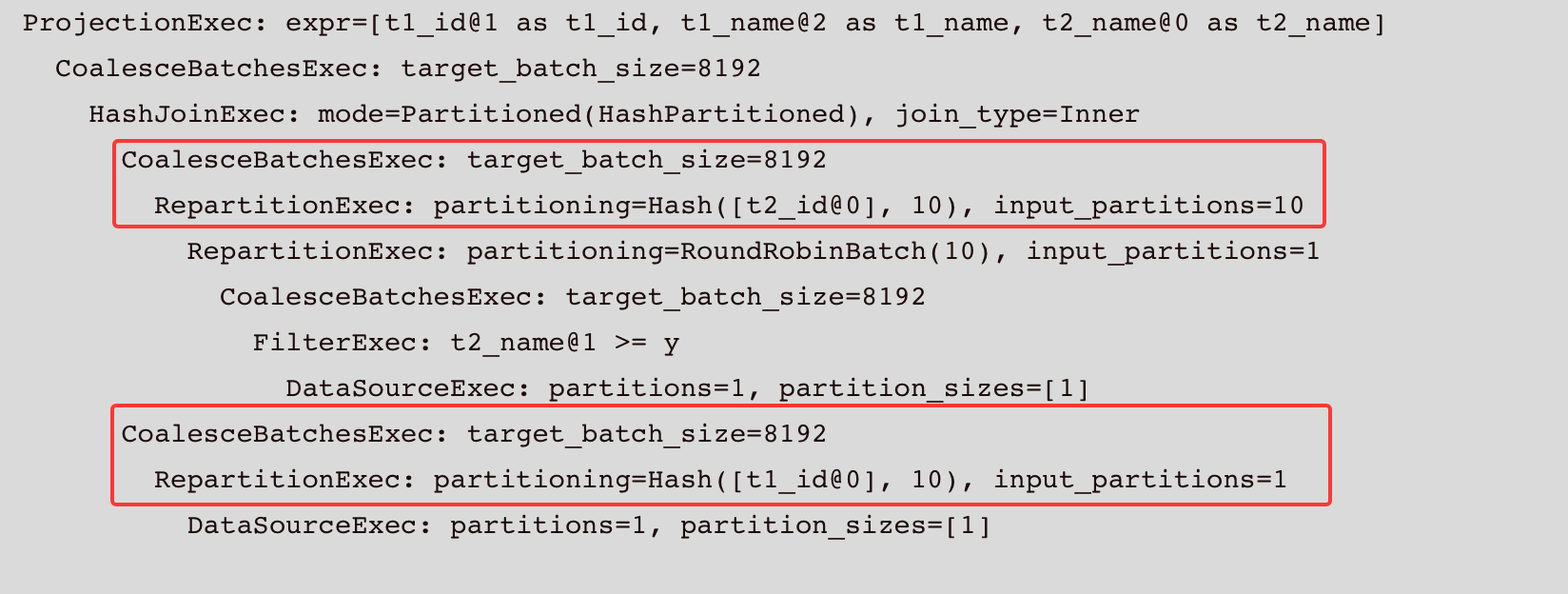
根据上文的介绍,实现后physical plan变为:

可以看到在RepartitionExec后无需进行CoalescesBatchesExec。