Hash Join利用了哈希表查询的优势,实现了更好的并行化。
Probe Side vs Build Side
Hash Join有两个输入,Build Side和Probe Side。Build Side会加载到内存中构建哈希表,Probe Side会流式与该哈希表进行处理。根据此特点,更小的输入会作为Build Side。
下图描述了Build Side哈希表与Probe Side batches进行处理的流程:
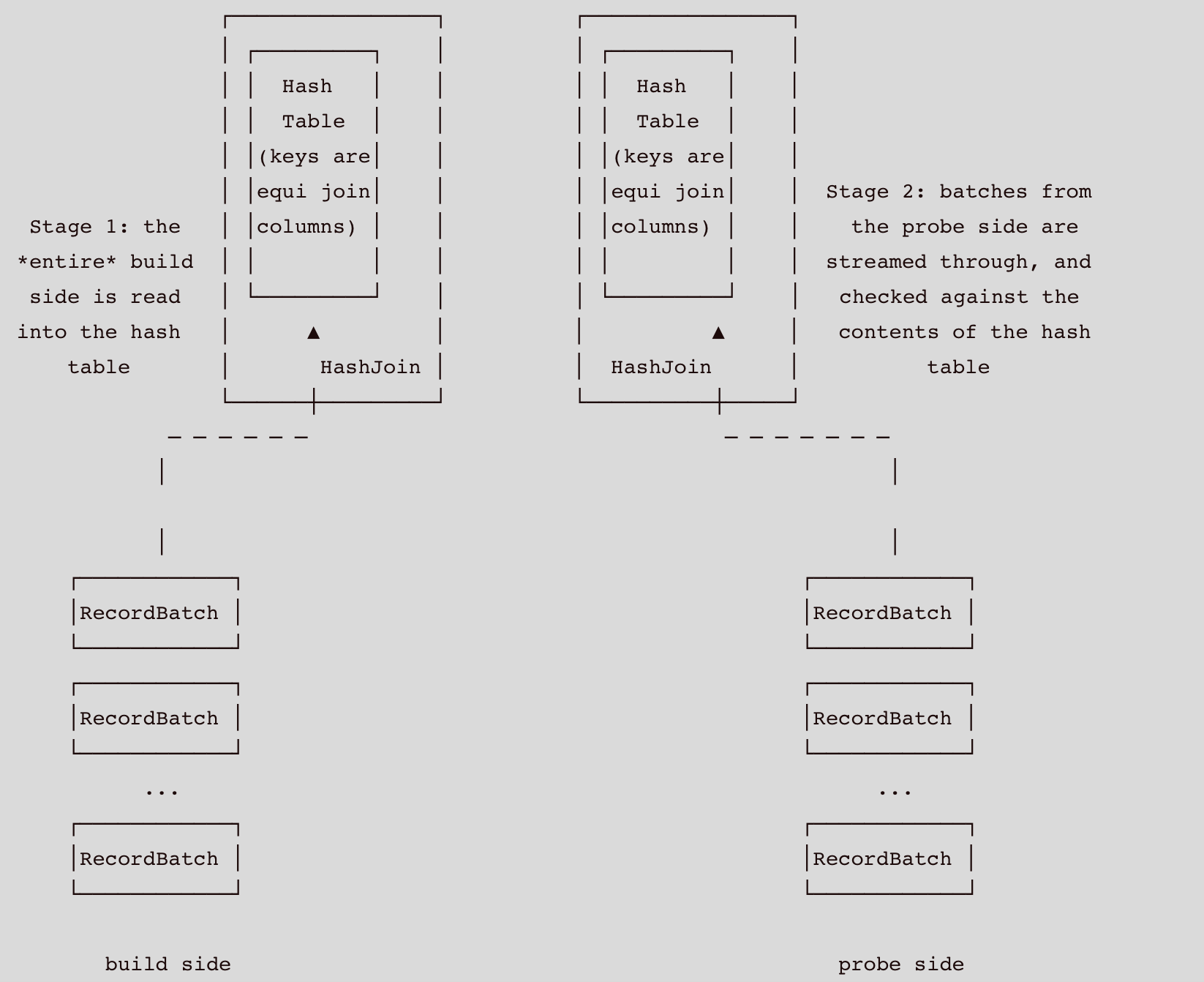
Partition Mode
CollectLeft:左表全量加载到内存中构建哈希表,被所有Probe Side的线程共享。
Partitioned:左右表按照Join Keys进行哈希分区,再处理左右对应的分区。注意:左右分区数相同,且hash % num_partitions保证了相同的Join Keys一定在相对应的分区。
Auto:在map_logical_node_to_physical中会初始化为Auto模式,后续Optimizer会根据统计信息选择最优策略:
- 当左侧数据量小于配置阈值(包括字节大小和行数阈值)时,选择 CollectLeft ,否则Partitioned
- 当数据量超过阈值时,选择 Partitioned
- 统计信息不可用时,选择 Partitioned
执行
举例说明执行阶段:
有表t1 t2
t1:
| T1_id | T1_name |
|---|---|
| 11 | 'z' |
| 22 | 'y' |
| 44 | 'x' |
| 55 | 'w' |
t2:
| T2_ID | T2_name |
|---|---|
| 11 | 'a' |
| 22 | 'b' |
| 33 | 'c' |
| 44 | 'd' |
现有sql语句:
SELECT t1_id, t1_name, t2_name FROM t1 JOIN t2 ON t1_id = t2_id AND t2_name >= 'x';
阶段1:构建Build Side
因为有一个filter push down,t1和t2的数据量在filter后相比,t2更小一点,所以可能会swap inputs,将t2作为Build Side。
根据Record Batches构建哈希表,t2_id作为Key,indices即索引作为Value。
此时有Build Side:
| indices | t2_ID | T2_NAME |
|---|---|---|
| 0 | 11 | 'a' |
| 1 | 22 | 'b' |
| 2 | 33 | 'c' |
| 3 | 44 | 'd' |
阶段2: 处理Probe Side
流式读取Probe Side的数据进行处理,假设有Probe Side批次如下:
| indices | t1_ID | T1_NAME |
|---|---|---|
| 0 | 11 | 'z' |
| 1 | 22 | 'y' |
查找
先与哈希表进行匹配。有两条数据匹配:
t1 [11,'z'] [22,'y']
| |
| |
t2 [11,'a'] [22,'b']
生成相应的索引:
Build indices: 0, 1
Probe indices: 0, 1
过滤
使用非等值连接条件进行过滤
处理右表未处理的行
根据 join 类型调整行索引
- inner join,则不调整
- left join,在第三阶段输出未匹配的左表数据
- right join,追加右表未匹配的行
- full join,跟 right join 类似,不过还会在第三阶段输出未匹配的左表数据
生成Batch
通过indices以及projection输出结果
阶段3: 处理左表未处理的行
根据 join 类型进行输出 (在第二阶段会标记哪些行被输出了)
- inner join,则不处理
- full join或者left join,输出未匹配的左表数据
- right join,已经在第二阶段处理了
优化规则
TODO